Protected data & AI: Are your models using data they shouldn’t?

Imagine two people: John Smith and Jane Doe. John lives in a suburban area with his wife. He has a graduate degree and works for a large company. He has no children and a good credit history. By contrast, Jane is unmarried and lives in a rural area. She does not have a degree, is self-employed, and has one child. She also has a good credit history and the exact same yearly income as John.
Now imagine John and Jane both walk into a bank today and apply for loans of identical amounts and payment terms. Given that they have the same income and credit history, the bank should assess both of their applications equally and should come to the same conclusion. However, banks that use machine learning as part of their loan approval process may be introducing discrimination into the process and may not be looking at the applications equally.
How can machines be discriminatory?
Discrimination in machine learning (ML) is best demonstrated with an example. Here is a dataset with the same types of data about loan applications and approvals that banks would use to create a machine learning model. In addition to whether the loan approval decision, this dataset includes the applicant’s:
- Gender
- Marital status
- Number of dependents
- Level of education
- Income
- Employment history
- Loan amount and loan terms
- Credit history
- Where the applicant lives (i.e., urban, semi-urban, or rural area)
Using a dataset like this as an input, a bank could create an ML model that predicts the probability of a person being approved or denied for a loan application. This model benefits the bank because it automates the approval process, freeing up their financial advisor’s time to do other tasks.
If the bank were to apply an ML technique called a “logistic regression” to this dataset and then compare the results of the model’s automated decision making (ADM) to their financial advisor’s decision making, it would look like this:
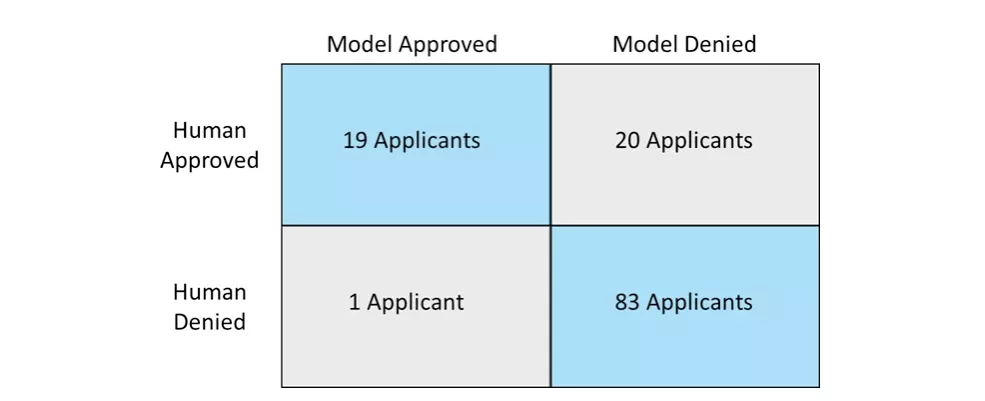
For the 123 loan applications tested, the model and the human advisor would have come to the same conclusion on whether to approve or deny the loan in 83% of cases, with the model being more conservative in terms of approvals than human advisors. In short, by using this model, the bank would have a relatively effective machine-learning-based ADM system.
So how is that biased?
When performing a deeper analysis, a less flattering picture of the model appears.
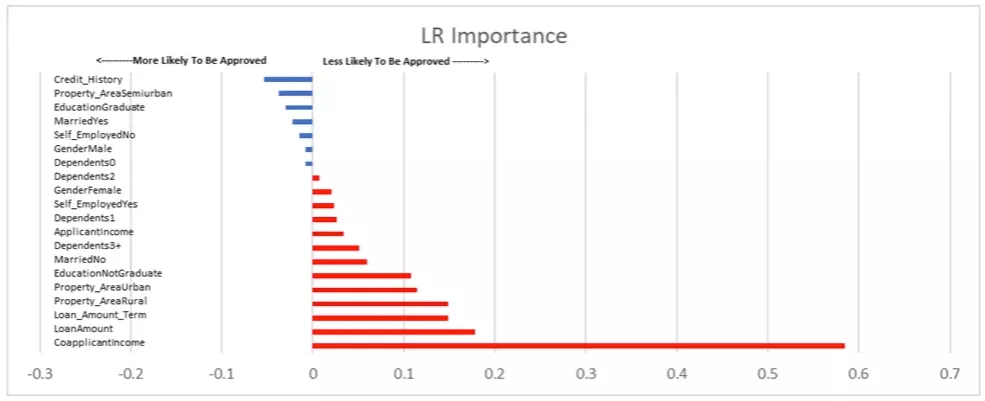
The above chart ranks the inputs of the model in terms of how they contributed to the loan approval decision. The characteristics in blue are the ones that make approval more likely, and the ones in red make approval less likely. Additionally, the bar’s length represents the magnitude of influence the characteristic has over the model. Put simply, a shorter bar has less influence, and a larger bar has more influence.
For example, as someone’s credit history improves, the model increases their likelihood of loan approval. Conversely, if an applicant must include co-applicant income as part of their loan application, the model decreases their likelihood of loan approval.
How much does it matter?
Returning to the example of John Smith and Jane Doe, the model gives a 71% probability that John’s application will be approved. By contrast, Jane’s application has only a 52% probability of being approved. This is especially disturbing given that both Jane and John are identical in terms of the characteristics that directly affect their ability to repay the loan: namely, their income and credit history.
While John and Jane themselves are fictional, the idea of machine learning introducing discrimination into automated loan approvals is a very real risk. In November 2019, a high-profile tech entrepreneur named David Heinemeier Hansson posted a scathing review about Apple’s new credit card program. In it, he revealed that the artificial intelligence (AI) algorithm that Apple was using to determine creditworthiness had given his wife 5% of his credit limit. He felt this was especially egregious given that they file joint tax returns and live in a community property state, meaning that they are equally responsible for any credit card debt.
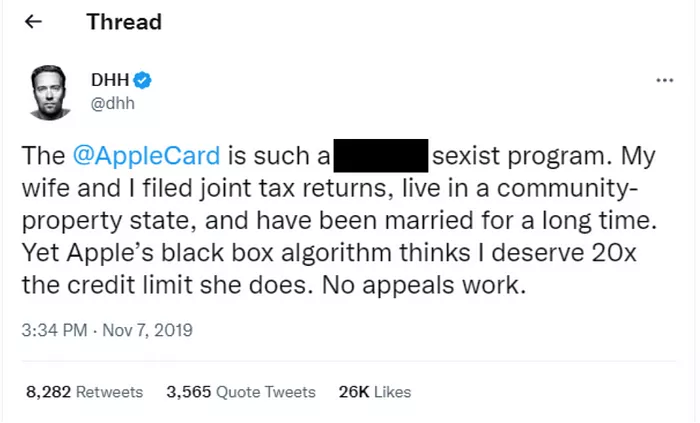
While Apple was ultimately cleared of any discriminatory practices, it led to regulators in the US, UK, and EU passing several pieces of legislation to ensure that organizations using AI to make decisions are not inadvertently discriminating against protected groups — a practice that many organizations still struggle with today.
Why should organizations care?
Ethical and reputational considerations aside for a moment, organizations that use protected data to make automated decisions are at risk from a regulatory perspective. There are multiple data responsibility and privacy requirements in nearly all 50 states and several countries around the world. These regulations are broad, covering personally identifiable information, personal financial information, and personal health information.
Additionally, as artificial intelligence (AI) and ML become more prevalent, many states are beginning to adopt laws that protect data subjects’ rights when included in AI-assisted data processing activities. While the US does not have a federal AI/ML standard in place yet, several countries and even some states do. In California, for example, there are already laws in place that prevent the use of AI profiling and ADM systems to process certain industry-specific applications and data sets. In 2022 alone, over 100 pieces of legislation across 30 states were introduced that target AI/ML data processing in some way.
The consequences of breaking these regulations are severe. Fines can range from a percentage of the enterprise’s gross yearly earnings to a granular per-violation approach for each incident determined to be out of compliance. Typically, the fine ceiling is ‘whichever is higher’. Moreover, enforcement of the EU AI Act is like the GDPR — meaning the legislation has extrajudicial reach for data outside of the EU.
It’s also worth noting that for all practical purposes, the rules currently focus on “explainable AI” as a data subject right, meaning that if an organization cannot clearly explain to a lay person how AI came to a decision, then you cannot use that system to process the person’s data. Given the complex nature of AI, this represents a significant challenge.
What happened to organizations that broke the rules?
Ethical and reputational considerations aside for a moment, organizations that use protected data to make automated decisions are at risk from a regulatory perspective. There are multiple data responsibility and privacy requirements in nearly all 50 states and several countries around the world. These regulations are broad, covering personally identifiable information, personal financial information, and personal health information.
Additionally, as artificial intelligence (AI) and ML become more prevalent, many states are beginning to adopt laws that protect data subjects’ rights when included in AI-assisted data processing activities. While the US does not have a federal AI/ML standard in place yet, several countries and even some states do. In California, for example, there are already laws in place that prevent the use of AI profiling and ADM systems to process certain industry-specific applications and data sets. In 2022 alone, over 100 pieces of legislation across 30 states were introduced that target AI/ML data processing in some way.
The consequences of breaking these regulations are severe. Fines can range from a percentage of the enterprise’s gross yearly earnings to a granular per-violation approach for each incident determined to be out of compliance. Typically, the fine ceiling is ‘whichever is higher’. Moreover, enforcement of the EU AI Act is like the GDPR — meaning the legislation has extrajudicial reach for data outside of the EU.
It’s also worth noting that for all practical purposes, the rules currently focus on “explainable AI” as a data subject right, meaning that if an organization cannot clearly explain to a lay person how AI came to a decision, then you cannot use that system to process the person’s data. Given the complex nature of AI, this represents a significant challenge.
What can organizations do to avoid violating AI regulations?
Removing bias from ML models is not a straightforward task. While some characteristics, such as gender or marital status, may lead to obvious bias in models, other characteristics are much more subtle. The legal environment surrounding AI is also in flux, meaning that organizations will have to continually stay up to date on the latest legislation and how it applies to their ADM. While no “silver-bullet” future-proofing solution exists, the best organizations adopt proactive, transparent data processing and protection practices — including clear opt-in mechanisms for any AI/ML processing. This includes taking the following four actions:
- Have a documented process in place to review AI models and processes annually. This review should be conducted by a neutral 3rd party and include a cross-functional team of experts, including machine learning engineers, data scientists, and legal experts who are fluent in the relevant legislation. Ideally, this team should also be able to provide guidance on how to remove protected data while retaining the model’s accuracy.
- Ensure data subjects can easily access data processing, data privacy, and data protection policies. Make sure data subjects and consent articles are clear to people who do not understand AI. Include an easy-to-use customer self-service portal and consent management platform for customers to change their data preferences.
- Make all points of algorithmic interaction obvious. This should include online forms, chatbots, and anywhere an algorithm is being used to make decisions.
- Have a documented process in place to communicate with data subjects in case of harm, as well as a documented process in place to communicate with regulators and authorities according to the laws and customs of the countries from which you process data.
Organizations that take these actions can lessen the risks associated with using AI while still enjoying the benefits.
Moving to customer-focused AI
AI is a powerful new tool for organizations to improve the efficiency of their operations and make more consistent decisions. However, like all powerful tools, it has the potential for misuse — the consequences of which can be dire. By carefully reviewing the inputs to their models, organizations can avoid the fines of regulators while still taking advantage of all the benefits AI affords.
This blog post was originally published here.